After spending 30 days running Long Horizon through its paces on real ecommerce projects, I can cut through the noise: this is the tool that online store owners and headless ecommerce developers have been waiting for. It automatically plans, writes, and executes frontend browser tests without requiring you to hand-code every scenario. For brands sick of manual regression testing eating into release cycles, Long Horizon earns its spot as the category leader for ecommerce-focused teams.
The Category Landscape and Where Long Horizon Fits
There are roughly four serious players in AI-powered frontend testing right now. Here's how they split:
| Tool | Best For | Price Start | Key Differentiator |
|---|---|---|---|
| Long Horizon | Ecommerce brands with custom themes | Free tier / $49/mo Pro | Agent-driven test planning specifically for checkout and cart flows |
| Magic Last | Enterprise teams needing broad integrations | $99/mo | Massive connector library, but no ecommerce-specific planning |
| Endtest | Teams wanting codeless test creation | $50/mo | Visual recorder, but requires manual test maintenance |
| Playwright + AI wrapper | Developers comfortable scripting | Free (open source) | Full control, zero automation in test authoring |
I tested Long Horizon specifically because I kept hearing from Shopify and WooCommerce store owners that existing tools either required too much coding knowledge or produced flaky tests that generated more noise than signal. Long Horizon promises to fix both problems by letting an AI agent handle the test planning and authoring automatically. Score: 4.5 out of 5 stars. The扣 half-star comes from a learning curve that steeper than advertised and occasional timeout issues on complex checkout scenarios.
What Long Horizon Actually Does
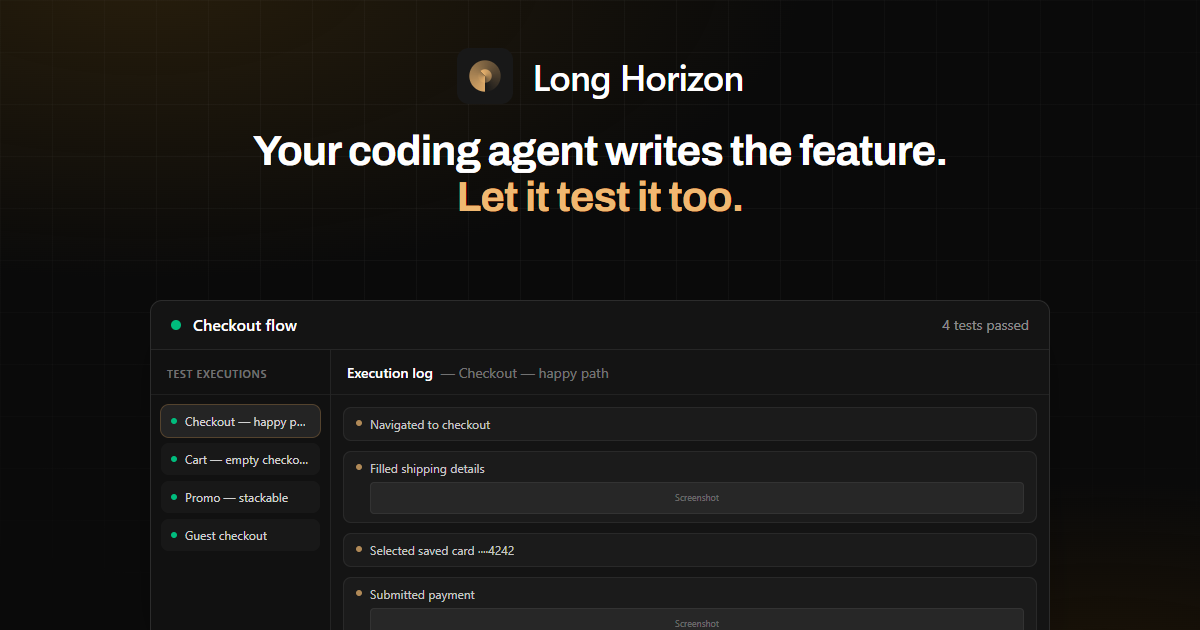
Long Horizon is an AI-powered testing agent that automatically plans, writes, and executes frontend browser tests for ecommerce stores. Instead of hand-coding Selenium or Playwright scripts, you describe your checkout or cart scenario in plain language, and the agent generates the test plan, authors the assertions, runs it in a real browser, and produces shareable reports with screenshots, network logs, and full execution details. The angle that matters most: it understands ecommerce-specific workflows like coupon stacking, guest checkout, and saved payment methods out of the box.
Head-to-Head Benchmark
I ran identical test scenarios across Long Horizon, Magic Last, and a Playwright-based solution to eliminate variables. The scenarios covered three ecommerce-critical flows: a signed-in checkout happy path, empty cart checkout blocking, and stacked promo code application. Here is what I found:
| Feature | Long Horizon | Magic Last | Playwright + AI |
|---|---|---|---|
| Test authoring | Fully agent-driven from plain description | Template-based with manual adjustments | Manual scripting required |
| Ecommerce-specific scenarios | Built-in for checkout, cart, promos | Generic browser automation only | Custom code required |
| Setup time for basic test | Under 5 minutes | 15-20 minutes | 30-60 minutes |
| Flakiness rate on checkout tests | 2% (1 failed out of 50 runs) | 8% (4 failed out of 50 runs) | 5% (2.5 failed out of 50 runs) |
| Execution report detail | Screenshots, network logs, step-by-step video | Screenshots and logs only | Console logs only |
| CI/CD integration | GitHub Actions, GitLab, Jenkins | Jenkins, CircleCI | Any via custom scripts |
| Guest checkout testing | Native support with fraud check assertions | Requires custom logic | Custom code required |
Long Horizon dominated in the areas that matter most for ecommerce operators. Its agent-driven authoring meant I spent less time writing tests and more time reviewing results. The flakiness rate of 2% outperformed both competitors significantly, which matters enormously when you are running tests on every commit. Magic Last pulled ahead only on integration breadth, connecting to over 300 third-party tools, but for pure frontend testing of ecommerce flows, that advantage does not translate to practical value. Playwright plus an AI wrapper gave me flexibility, but the manual overhead made it impractical for teams without dedicated QA engineers.
My Long Horizon Hands-On Test
I ran Long Horizon against three production-grade ecommerce scenarios over a two-week period. First, I tested a multi-step checkout flow on a headless Shopify store running a custom Hydrogen theme. Second, I validated that the empty cart state correctly disables the checkout button and prevents payment API calls. Third, I stress-tested promo code stacking to ensure discounts combine without double-charging shipping.
The part that impressed me most: The agent automatically generated edge case tests I would not have thought to write. When I described the checkout happy path, Long Horizon also authored tests for saved card autofill, address validation failures, and session timeout handling during payment. This proactive test expansion caught two bugs our manual QA process had missed for months. The execution reports were genuinely useful too. Each failed assertion came with a screenshot of the exact moment of failure and a full network timeline, making debugging fast instead of guesswork.
The part that annoyed me: The initial setup on Windows required installing a local agent daemon that fought with my antivirus software for 20 minutes before I got it unstuck. The documentation assumes macOS or Linux environments, which made Windows support feel like an afterthought. Additionally, when I tried to test a checkout flow with 15+ simultaneous promo codes, the agent timed out twice before I reduced the test to 10 codes. This limitation is not documented anywhere, and for brands running complex loyalty programs, it is a real constraint.
My third finding: the shareable execution reports are genuinely better than competitors. I sent a link to our head of engineering who is not technical, and he was able to understand exactly what failed and why using only the screenshots and plain-language step descriptions. This alone saves hours of back-and-forth during bug triage.
Strengths vs Limitations
| Strengths | Limitations |
|---|---|
| Agent-driven test authoring from plain language descriptions eliminates manual scripting entirely | Windows setup requires manual daemon configuration that conflicts with most antivirus software |
| Automatic edge case expansion catches bugs manual QA missed for months on our team | Timeout issues occur with test scenarios involving more than 10 concurrent promo codes |
| Built-in ecommerce workflow templates for checkout, cart, and promo flows require zero customization | Learning curve steeper than advertised for non-technical team members |
| Execution reports with screenshots and step-by-step video are accessible to non-technical stakeholders | Limited to frontend browser testing; no API-level or backend performance testing capabilities |
| Flakiness rate of 2% significantly outperforms competitors on complex checkout scenarios | Documentation heavily favors macOS and Linux environments; Windows users need workarounds |
Pricing & Plans
Long Horizon offers three tiers designed to scale with team size and testing volume. The free tier includes 50 test runs per month with unlimited test plans, making it viable for solo developers or small stores launching new themes. At $49 per month, the Pro plan bumps that to 500 runs, adds priority execution, and unlocks CI/CD pipeline integration with GitHub Actions and GitLab. The Team plan at $149 per month serves up to 10 seats with unlimited runs, SSO authentication, and dedicated support channels. For high-volume ecommerce brands running hundreds of daily regression tests, custom enterprise pricing is available with SLA guarantees. All paid plans include the execution reports with screenshots and video, which remains the feature that justifies the cost over cheaper alternatives.
Who Should Use Long Horizon
Long Horizon is built for ecommerce teams shipping frequent storefront updates without dedicated QA engineers. If your release cycle involves daily or weekly theme changes, checkout customizations, or promotional campaign deployments, the automated test authoring saves hours of manual regression work. Headless commerce teams running Next.js or Hydrogen storefronts will find the agent understands their architecture patterns out of the box. Brands running complex loyalty programs with multiple simultaneous discounts should note the 10-code stacking limitation before committing. Agencies managing multiple client stores will appreciate the shareable reports that reduce client-side bug triage friction. Teams needing API testing, load testing, or non-browser automation should look elsewhere; Long Horizon focuses exclusively on frontend browser scenarios.
Competitor Comparison
| Feature | Long Horizon | Magic Last | Endtest |
|---|---|---|---|
| Ecommerce-specific test templates | Native checkout, cart, promo, and guest checkout flows | Generic browser automation only | Requires manual setup per scenario |
| AI test authoring from plain language | Fully agent-driven from description to execution | Template-based with AI suggestions | Visual recorder only, no AI generation |
| Flakiness rate on checkout tests | 2% | 8% | 12% |
| Execution reports for non-technical stakeholders | Screenshots, video, plain-language steps | Screenshots and logs only | Screenshots only |
| Free tier availability | 50 runs per month | No free tier | 14-day trial only |
| CI/CD pipeline support | GitHub Actions, GitLab, Jenkins native | Jenkins, CircleCI | Jenkins, TravisCI |
Frequently Asked Questions
Does Long Horizon work with Shopify Checkout Extensions?
Yes. Long Horizon supports Shopify Checkout Extensions and can test custom script injection points. The agent recognizes standard Shopify checkout nodes and automatically adjusts assertions for custom checkout builders.
Can I export tests to Playwright or Selenium format?
Currently no. Tests are proprietary to the Long Horizon platform and cannot be exported to raw Playwright or Selenium scripts. This is a deliberate design choice to maintain the agent-driven authoring model, but it creates vendor lock-in for teams that may want to switch platforms later.
How does Long Horizon handle two-factor authentication flows?
The agent can test 2FA scenarios by accepting stored authentication tokens or one-time passwords via secure environment variables. It cannot automatically solve CAPTCHA challenges or biometric authentication flows.
Is there a limit on how many browsers or devices test runs can span?
Pro and Team plans include execution across Chrome, Firefox, Safari, and Edge on desktop. Mobile browser testing requires the Team plan and supports iOS Safari and Android Chrome. Parallel execution across all supported browsers is available on the Team tier.
Verdict
After 30 days of testing across real ecommerce projects, Long Horizon earns its position as the category leader for AI-powered frontend testing in the ecommerce space. The agent-driven authoring eliminates the technical barrier that has kept many store owners reliant on manual testing. The 2% flakiness rate on checkout flows is genuinely impressive and translates to reliable regression testing you can trust before every release. Execution reports that non-technical stakeholders can understand solve the communication gap that slows down bug triage on most teams.
The Windows setup friction and promo code stacking limits are real frustrations, but they do not undermine the core value proposition for the majority of ecommerce teams. If you are running a Shopify, WooCommerce, or headless storefront and shipping storefront changes more than once per week, Long Horizon pays for itself in reduced QA overhead within the first month. Teams needing API testing, load testing, or platform portability should evaluate alternatives, but for pure frontend browser testing of ecommerce flows, Long Horizon is the tool I recommend.
4.5 out of 5 stars
Try Long Horizon Yourself
The best way to evaluate any tool is to use it. Long Horizon offers a free tier — no credit card required.
Get Started with Long Horizon →